

温故知新 | mydumper & dumpling 知识点汇总
“温故知新”系列,是指重新整理汇总那些有用但可能平时用不到的知识点,同时发掘、学习新的知识点以丰富知识体系。
本文主要阐释 mydumper 和 dumpling 工具的相关概念、使用方法,及其与TiDB的关联。
前置信息:
CentOS Linux release 7.9.2009 (Core)
MySQL 5.7.37
TiDB v5.4.0
mydumper v0.11.5-2
mydumper v0.9.5 with PingCAP customization
dumpling v5.4.0
mydumper 简介
mydummper是一个第三方工具,用来备份 MySQL(MariaDB、Percona)数据库。
缘起
The mydumper project was started at the beginning of 2009 by Domas Mituzas, and a few months ago we started collaborating and adding new features to improve performance and usability.
via. Percona Blog.
特性
- 支持多线程导出数据,速度更快。
- 支持一致性备份。
- 支持将导出文件压缩,节约空间。
- 支持多线程恢复。
- 支持以守护进程模式工作,定时快照和连续二进制日志。
- 支持按照指定大小将备份文件切割。
- 数据与建表语句分离。
- 比mysqldump速度快。
代码
最新版代码库:
安装
这里介绍两种安装方式:1. RPM安装;2. 源码编译安装
- RPM安装
1 | yum install -y https://github.com/mydumper/mydumper/releases/download/v0.11.5-2/mydumper-0.11.5-2.el7.x86_64.rpm |
- 源码编译安装
1 | # yum install -y cmake gcc gcc-c++ git make |
mydumper 使用方法
重要选项
摘取了一些重要的选项,列举如下:
| Options | Desc |
|---|---|
| -B, --database | 导出的源库 |
| -T, --tables-list | 导出的表,以逗号分隔(不排除正则选项) |
| -o, --outputdir | 输出文件到目标目录 |
| -F, --chunk-filesize | 将表按指定块大小(单位为MB)拆分成若干文件 |
| -c, --compress | 压缩输出文件 |
| -x, --regex | 正则表达式去匹配 ‘db.table’ |
| -m, --no-schemas | 只备份表数据,不备份表结构 |
| -d, --no-data | 不备份表数据 |
| -k, --no-locks | 不执行临时共享读锁。警告:这将导致不一致的备份 |
| -t, --threads | 使用的线程数,默认值为4 |
| – | – |
| –sync-wait | WSREP_SYNC_WAIT value to set at SESSION level |
| – | – |
| -z, --tidb-snapshot | Snapshot to use for TiDB |
注:
-z 或 --tidb-snapshot: 设置 tidb_snapshot 用于备份。默认值为当前 TSO(SHOW MASTER STATUS 输出的 Position 字段)。此参数可设为 TSO 或有效的 datetime 时间,例如:-z “2016-10-08 16:45:26”。--no-locks: 在阿里云一些需要 super privilege 的云上面,mydumper 需要加上 --no-locks 参数,否则会提示没有权限操作。
常用备份命令
1 | 连接信息 |
备份文件命名
常见命名规则:
- metadata: 记录备份的开始、结束时间。
- database-schema-create.sql: 建库语句。
- database.table.sql: 该表的插入数据语句(若该表为空,则不存在此文件)。
- database.table-metadata: 记录该表的行数。
- database.table-schema.sql: 该表的创建语句。
mydumper 支持 TiDB
官方版本的 mydumper 对 TiDB 的支持。
或者说,PingCAP 团队以将 mydumper 对 TiDB 的兼容性代码向上游提交 PR 并完成合并。
https://github.com/mydumper/mydumper/pull/155/
- Add version detection for TiDB (detected_server).
- Added support for tidb_snapshot option.
- Auto-set tidb_snapshot to 1 second ago when TiDB detected.
- Added optimization to dump _tidb_row id when it exists.
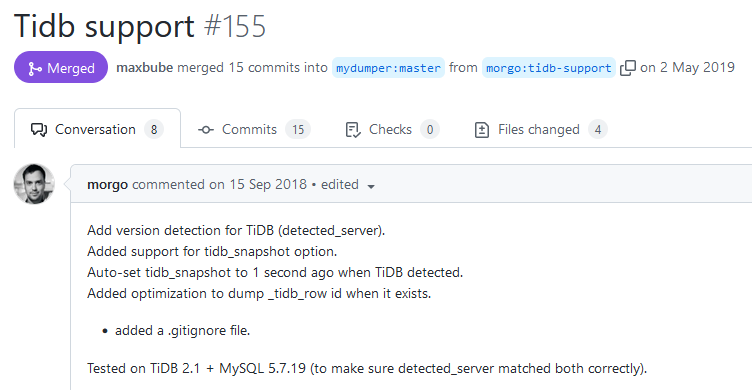
另外,从网络图中我们可以看出,从16年10月开始,PingCAP创建了新的分支版本,并开始兼容性开发。
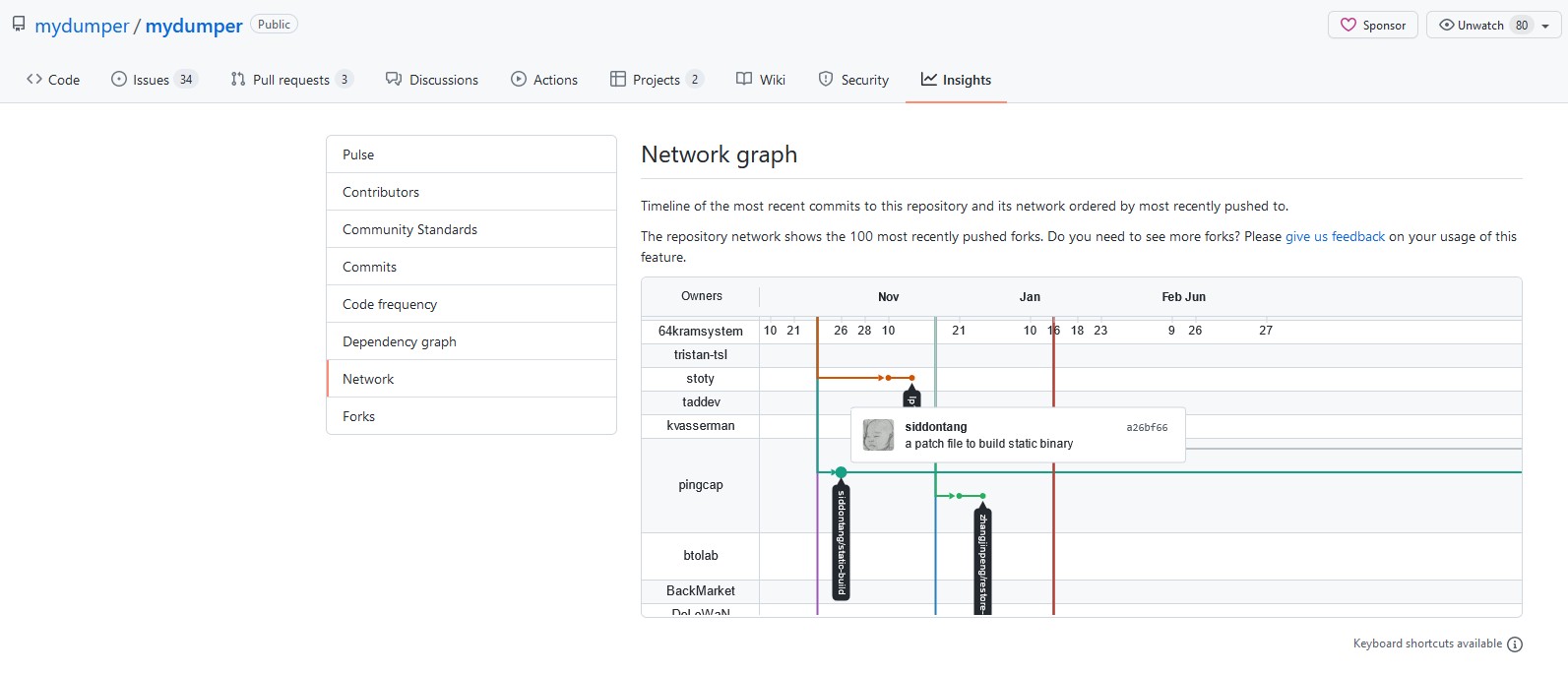
从 pingcap/mydumper 的代码提交记录和PR来看,定制版 mydumper 虽然依旧支持 TiDB v5,但是由于从 TiDB v4 开始已经正式发布了 dumpling 工具,并被其取代。同时,我们也可以清晰的从官方文档里看到这样的一条警告 :
PingCAP 之前维护的 Mydumper 工具 fork 自 mydumper project,针对 TiDB 的特性进行了优化。Mydumper 目前已经不再开发新功能,其绝大部分功能已经被 Dumpling 取代。Dumpling 工具使用 Go 语言编写,支持更多针对 TiDB 特性的优化。强烈建议切换到 Dumpling。
Dumpling 简介
Dumpling 一个支持热、温备的逻辑备份工具,是 mydumper 的全新升级版,基本用法类似于 mydumper,但也有所区别,可使用tiup进行管理。
Dumpling 从19年12月开始着手开发,使用Go语言编写,整合了 mydumper 的原有功能,并做了一些改进。
代码
- 原始代码库:https://github.com/pingcap/dumpling
- 最新代码库:https://github.com/pingcap/tidb/tree/master/dumpling
注:
Dumpling merged into TiDB (#379 )
Dumpling 的改进
相比 Mydumper,Dumpling 做了如下改进:
-
支持导出多种数据形式,包括 SQL/CSV。
通过选项--filetype string进行控制,可以选择sql或csv。
关于CSV格式还有4个相关参数:
--csv-delimiter, csv文件中的定界符 (default “"”)。
--csv-null-value, csv中的null值 (default “\N”)。
--csv-separator, csv文件中的分隔符 (default “,”)。 -
支持全新的
table-filter,筛选数据更加方便。
整合了列表方式和正则方式,通过选项-f, --filter strings进行控制,默认值为:[*.*,!/^(mysql|sys|INFORMATION_SCHEMA|PERFORMANCE_SCHEMA|METRICS_SCHEMA|INSPECTION_SCHEMA)$/.*]
语法可参考: README -
支持导出到 Amazon S3 云盘。
增加了一系列 S3 相关选项,具体有:
1 | --s3.aclstring |
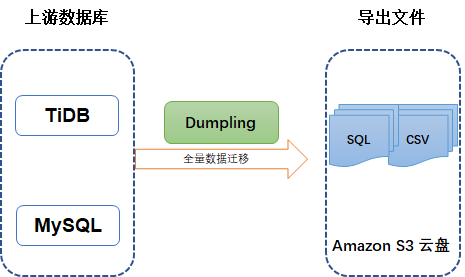
注:Export data to Amazon S3 cloud storage
- 针对 TiDB 进行了更多优化:
-
支持配置 TiDB 单条 SQL 内存限制。
通过选项--tidb-mem-quota-query uint进行控制,单位为 bytes。 -
针对 TiDB v4.0.0 及更新版本支持自动调整 TiDB GC 时间。
TiDB GC 相关概念可参考官方文档: -
使用 TiDB 的隐藏列
_tidb_rowid优化了单表内数据的并发导出性能。 -
对于 TiDB 可以设置 tidb_snapshot 的值指定备份数据的时间点,从而保证备份的一致性,而不是通过
FLUSH TABLES WITH READ LOCK来保证备份一致性。
相关参数:--snapshot string,需要配合参数--consistency=snapshot一起使用。
参数--consistency用于设定导出数据一致性级别,可设定为:
1, auto: 默认值,MySQL flush, TiDB snapshot
2, none: 不加锁 dump,无法保证一致性
3, flush: dump 前用 FTWRL
4, lock: 对需要 dump 的所有表执行 lock tables read
5, snapshot: 通过 tso 指定 dump 位置
-
Dumpling 所需权限
Dumpling 最小权限要求:select, reload, lock tables, replication client
创建用户示例:
1 | create user dumpling; |
常用备份命令
- DSN信息
1 | dsn='-u root -P 4000 --host 10.180.0.36' |
- 采用默认值直接执行备份
1 | tiup dumpling |
- 备份全库,备份文件格式为csv(
--filetype),以8个线程执行备份(-t),指定备份目录(-o),并将日志输出到指定文件(-L)
1 | tiup dumpling $dsn --filetype csv -t 8 -o ${bk_dir}-`bk_time` -L ${bk_dir}-`bk_time`.log |
- 备份指定表(
--database,-T),输出文件按2000行进行分块,并发执行数据导出到不同文件,以提升效率(-r);输出的文件按256MB进行拆分(-F)
1 | tiup dumpling $dsn --database sbtest -T sbtest.t1 -r 2000 -F 256MB |
- 备份指定表数据,
snapshot的时间点为 “2022-02-24 21:19:00”
1 | tiup dumpling $dsn -T sbtest.t1 --snapshot "2022-02-24 21:12:34" |
- 备份指定表数据, 并控制 TiDB 单条查询语句的内存限制为 1G (
--tidb-mem-quota-query)。
1 | tiup dumpling $dsn -T sbtest.t1 --tidb-mem-quota-query 1073741824 |
其他
使用 dumpling 时, 可将 tidb:performance.force-priority 优先级设定为 LOW_PRIORITY, 以降低备份对于集群的性能影响。
写在最后
如果您还在使用 TiDB v5.x 之前的版本,建议升级TiDB,mydumper 只需了解即可。
如果您已经在使用最新版的TiDB,那么一定要熟悉 Dumpling 的常规使用。
作为 Ti-DBA-er,我们应该对TiDB周边生态工具的过往、现在、未来都有所了解、熟悉,甚至参与其中。这样才能更好的维护线上TiDB,更有效的保障系统稳定性。
相关资源
- 官方文档 - Dumpling
- 301 TiDB 系统管理基础 -> L 18:数据导出工具 Dumpling
- 302 TiDB 高级系统管理 -> L 19:TiDB Server 关键性能参数与优化
- TiDB 认证 | PCTA 认证需要掌握的知识点
- TiDB 认证 | 新版 PingCAP PCTP 认证考试 – 备考指南
Yan
2022-02-24
https://www.modb.pro/db/335245
https://tidb.net/blog/6d3a8da2?shareId=4b720bab
- Title: 温故知新 | mydumper & dumpling 知识点汇总
- Author: 严少安
- Created at: 2022-02-24 22:02:49
- Updated at: 2022-02-24 22:02:49
- Link: https://shawnyan.cn/2022/tidb/mydumper-and-dumpling/
- License: This work is licensed under CC BY-NC-SA 4.0.


